


How do you build an AI voice model marketplace?
Is selling voice models a genuine new income stream for artists? Or is a fraudulent deepfake hellscape imminent? I spoke to DJ Fresh, Kits.ai and TuneCore CEO Andreea Gleeson to find out…

Hello! Straight up – this is a long one. But it requires a lot of explanation, as you’ll see below. As I started speaking to the people who graciously gave their time for this newsletter, I realised that the significant impact of this technology required a lot of context. And while AI is being hoisted up as the saviour, and destroyer, of literally everything, voice models do feel like a truly revolutionary creative technology that’s being rolled out, in real-time, in front of our eyes.
I wanted to find out how you build a product for a market that doesn’t exist yet, how you design a platform for users with no experience and how you compensate artists for work that has no pretence. There’s heaps to this one so I hope it gives you a good overview, until next week when it’s all out of date, and we go again.
Declan x
The Week in AI
SoundCloud says they’re going to tackle the ‘zero plays problem’ with an AI-powered ‘first fans’ feature.
Daisy Morales explores how Spotify uses AI on its platform.
TikTok parent company ByteDance says it’s launching an app called Ripple that turns a hummed melody into a full track with arrangement and backing tracks.
Bedroom Producers’ Blog surveyed 1,500 producers on how they feel about AI.
Building the Future

Of all the topics that have captured the zeitgeist around AI and music – and that’s a lot – voice models have undoubtedly been the most controversial. And for good reason – the voice is the most personal thing we have, it’s how we communicate, it’s how we express our emotions. It’s often what defines a song or a band, an artist’s career and identity. To co-opt it feels particularly invasive.
Add to that the replacement narratives that technology has always had to grapple with, the potential for deep fakes and fraud and the novelty aspect of singing, rapping or speaking as another person, and it’s become the go-to topic for many clickbait headlines over the past 18 months. The Drake and Weeknd story is the best example.
The topic dominated our panel at IMS Ibiza in April, where David Guetta’s long-time co-manager Jean-Charles Carré demoed how David had used the voice modelling website UberDuck.ai to create an AI version of Eminem that he then played at a show and recorded it for a viral video. The panel, which you can listen to here, also included Grimes’s manager Daouda Leonard – Grimes had only just announced her intentions to give away her voice to anyone for a 50% royalty split, so it’s worth listening to if you want to hear more about the conception of that idea. We’ll get into it below, too.
The debate around the ethics and morals of voice models is wide-ranging, thorny, complex and fascinating, and it’s a whole other topic from what I wanted to get into today. But to sum up my thoughts – as long as artists are protected at the source, and we can figure out a semi-watertight way to compensate those whose voices are being used, on their terms, I think we can get excited about the potential while avoiding a lot of the (significant) downsides.
The companies I spoke to for this newsletter are all trying to make that happen.
THE CREATIVE CONUNDRUM
Creativity is so often about getting your idea from conception to reality as fast as possible, before it’s gone, or before it’s compromised. Every time you introduce a new hurdle in bringing your idea to life, the more your idea suffers, the more the spark is gone. Especially if that hurdle is admin like finding an XLR cable or scrolling through 10,000 samples on your hard drive. Eliminating friction is the ultimate goal when it comes to creativity. Modern DAWs, sadly, very rarely allow for that, but that’s another topic (coming soon).
AI voice models introduce a whole new creative reality, one that’s initially hard to fathom. What if you could sing an idea or melody, and no matter what your vocal ability, have a perfectly recorded, autotuned and compressed studio version of what you just sang within a few minutes? What if you could upload your own acapella and select singers from a drop-down menu to sing it back to you, almost in real-time? What if you could write songs for another artist and use a model so they could hear the demo in their own voice, without ever going to the studio?
I spoke to three different companies that are exploring this new reality, each with a different USP and approach. I wanted to understand: How do you build something so new it has no framework ethically or legally? How do you explain to a vocalist or artist that their likenesses being rented and sold to anyone with an internet connection is a good thing for them and the wider music industry? And how do you create an interface that anyone at any skill level can understand and use, despite the complexity of the technology behind it? How do you also deal with a hostile industry that last week ordered Discord to shut down a prominent voice model server?
Let’s find out.

WHAT ARE VOICE MODELS?
First, it’s important to clarify what voice models actually are. Essentially, machine learning models use training data – usually a studio-quality acapella – to spot patterns in how a person sings, talks or raps.
Those patterns can be everything from their tone, timbre, how they emphasise consonants, how they approach vibrato, how they breathe between words, their vocal range etc, etc – there are millions of data points that make up a model. When you then upload your voice as the source, the model applies these patterns and qualities to your recording, essentially transferring one person’s vocal style onto another’s.
The results can vary wildly depending on the quality of both the acapella and the model itself. In an ideal world, both the training data and the source would be of studio quality and free from FX like delay and reverb, they don’t necessarily have to be to get something usable.
One of the first artists to experiment with these theories and technologies as part of a commercial release was Holly Herndon. She created various voice models to collaborate with on her 2019 album Proto and went one further at a live show at SONAR in 2021 by recruiting her collaborator and partner Mat Dryhurst to sing in her voice – in real-time. Watch the video here. (I’d embed it if Elon allowed it, sad).
In 2022, she created a publicly accessible model of her own voice called Holly+. Users could upload their own acapella and hear their recordings sung by Herndon. It was revolutionary not just from a technical and creative perspective, but in the simplicity with which it allowed users to interact with these tools, right there in the browser. Once Herndon approved any tracks to be commercially released, any revenue from those releases went back into a DAO to fund more creative projects. You can read Herndon’s whitepaper here, which also explains how it works in more detail.

TUNECORE & GRIMES
Back in April of this year, Grimes tweeted she was giving away a model of her own voice, trained by her and her team, for free. Anyone who released music using the model on a streaming platform like Spotify had to split the derivatives with Grimes 50/50. A more formal process to submit music followed, subject to Grimes’ approval and the approval of her manager Daouda Leonard’s design and development company CreateSafe.io. You can try out your own voice as Grimes here.
In June 2023, CreateSafe and TuneCore launched a new distribution partnership, where TuneCore would take the reins on dealing with the traditional DSPs, splits and other metadata required when submitting a track for release, while CreateSafe would still manage the manual approval process associated with each upload using Elf Tech and GrimesAI, the official name for Grimes’s AI voice.
“Since this is unchartered territory for many of us, we wanted to make sure that a few core principles went into how we built the framework,” TuneCore CEO Andreea Gleeson told me via Google Meet. “We wanted to make sure it was clear Grimes gave consent, which she did very publicly already. But that's very important when we think about this particular use case of AI – making sure that there is clear artist consent.” TuneCore – a distribution company owned by French institution Believe – also wanted to put an approvals process in place to avoid any use of Grimes’s voice that would go against her and her team’s wishes. “[CreateSafe] tend to be very lenient because they prefer to allow as much creativity as possible. But it's important in this model that you enable [editorial control].”
Finally, the revenue split was a key part of the agreement. “[It was important that we] were really able to protect the revenue share setup and operationalise that. If Grimes says, ‘Hey, I need to have 50% [royalties] that come back to me if you use my voice,’ we had to make sure we enabled that. Those three principles are what drove the partnership.” TuneCore also published an FAQ about how you upload and release a GrimesAI collaboration.
OTHER VOICES
Right now, this partnership is only in place for Grimes’s AI voice, though Gleeson says more models are likely around the corner. “We are exploring making this available to other artists. But we're really approaching this as a crawl before you run [scenario].” Though she didn’t predict who those artists might be, CreateSafe has previously worked with Lady Gaga and Lil Nas X. GagaAI would be a lot of fun.
“We are exploring making this available to other artists. But we're really approaching this as a crawl before you run [scenario].” – Andreea Gleeson, TuneCore CEO
Of course, many questions still remain. Is the manual approvals process really scalable? Will every artist have to check every upload for hate speech or any other form of discrimination once models become commonplace? Gleeson was keen to point out that there are still many unknowns in how this technology will be adopted and used in the short-to-medium term.
“I don't know if it can be [checked manually] – it's gonna be up to the artists how much they want to have editorial control. We want to make sure we're enabling it. In the meantime, I think it’s best to keep the crawl-before-we-run kind of mentality until we really are able to do this.”
For Gleeson, consent has to be at the core of this new paradigm, to gain the trust of both major labels and rightsholders, and the artists themselves. “With Drake and the Weeknd, everybody was freaking out because there was no consent. There was no control, there was no revenue participation. And I think [because of] what we have built, even though right now it's very much a pilot setup and does have room to get more operationalised.”
WHY WOULD ARTISTS WANT THIS?
You might be reading this and wondering: ‘A 50% split of fractions of a penny of royalty payments really doesn’t seem worth it compared to the reputational damage that could be done, and the manual work involved in approvals.’ And that’s true! It really is a case-by-case scenario and no one is saying this is now the default and every artist must participate. It’s worth bearing in mind too, that the 50% split deal is Grimes’s own decision, and that other compensation models are being explored, which we’ll get to later.
There are also some super compelling reasons, beyond releasing music on traditional DSPs, that this new tech and these new models could be exciting for artists. One of them is fandom.
I recently wrote a piece for Resident Advisor about how artists can use Discord and in it, I explored some of the reasons ‘community’ has become a vital part of an artist ecosystem. You can read it here, but the gist is: opaque social media algorithms that change at a billionaire's whim have destroyed genuine connection online. In an attempt to reconnect, many artists are engaging fans in new, creative ways.
“Last year, Russ used TikTok’s dueting tool to release a verse and leave the other verse open and challenged his fanbase to complete it,” explained Gleeson. “There was a fan whose verse he loved, her name was Ktlyn, and he released a version of ‘Handsomer’ with her on it [listen here, she’s also in the music video. Russ says in the comments he paid $300k of his own money to make it happen]. I think there's this real desire to co-create with your fans, and [AI voice models] enable the ability to do that at scale, which I think is really interesting,” says Gleeson.
This won’t be a solution for everyone – you need to have a large fanbase to begin with, and you need to have a certain ‘artist universe’ that fans want to be a part of beyond the music itself, something Grimes has in abundance. But it’s an interesting concept that turns the traditional remix competition on its head and opens collaboration up to everyone, not just those with a DAW.
For me, probably the most practical use case of this technology isn’t trying to sound like a famous artist at all, but modelling yourself.
While it’s unlikely to grab the same Drake/Weeknd headlines, the idea of being able to lay down a studio-quality recording using your phone mic feels insanely valuable. If you can’t hit a high note, you can record someone who can and then use the model of your voice to get there. Always having a go-to, ‘perfect’ version of yourself is a really powerful concept, both practically and creatively. This is an area DJ Fresh has been exploring with his and developer Nico Pellerin’s new platform VoiceSwap.

A FRESH APPROACH
DJ Fresh, aka Daniel Stein, is better known to music fans as the man behind the imprint Breakbeat Koas, which brought Pendulum to the masses, as well as his own chart hits including ‘Gold Dust’ and ‘Hot Right Now’ with Rita Ora. He also founded the highly influential music forum Dogs on Acid. More recently, he stepped away from music making to focus on his original passion – software development and AI.
“I wanted to go right back to the beginning and get credibility in that world, so I did a three-month boot camp and got a job as a software engineer,” Stein told me on a call.
A whirlwind five years followed and he was eventually offered a job at Stability.ai, one he felt obliged to turn down. “On paper, it was an amazing job, but the more I dug into what they were doing, I didn’t feel like I could comfortably – as an artist – be associated with it. From then, I’ve been thinking, ‘How can you build an AI platform that is ethical, that does respect copyright, and is the kind of thing artists can get behind as opposed to being afraid of?’ And that’s what brought us to VoiceSwap.”
VoiceSwap is an AI voice model store, where users can subscribe for a monthly fee starting at £5.99 (one-off payments coming soon), upload an acapella and convert it to an existing singers’ voice. So far, VoiceSwap includes models from singers including Chase and Status and Shy FX collaborator Liam Bailey, Diplo vocalist and artist Dominique Young Brown and Rolling Stones, Grace Jones and Happy Mondays backing singer Angie Brown, also the voice of Bizarre Inc. What was the process like in convincing established artists to get involved in modelling their voices?
“When I first spoke to Liam Bailey about it, I can’t do his accent but he definitely used the words ‘the devil’,” laughs Stein. In the end, it was a phone call explaining how Bailey could use voice models in his collabs with other singers that sold him on the concept. “He’s writing for Paloma Faith at the moment and he said: ‘Wow if there’s a Paloma Faith model I would be able to write these songs and hear them in her voice and I could send them to her?’ and something switched in his mind and he was amazed.”
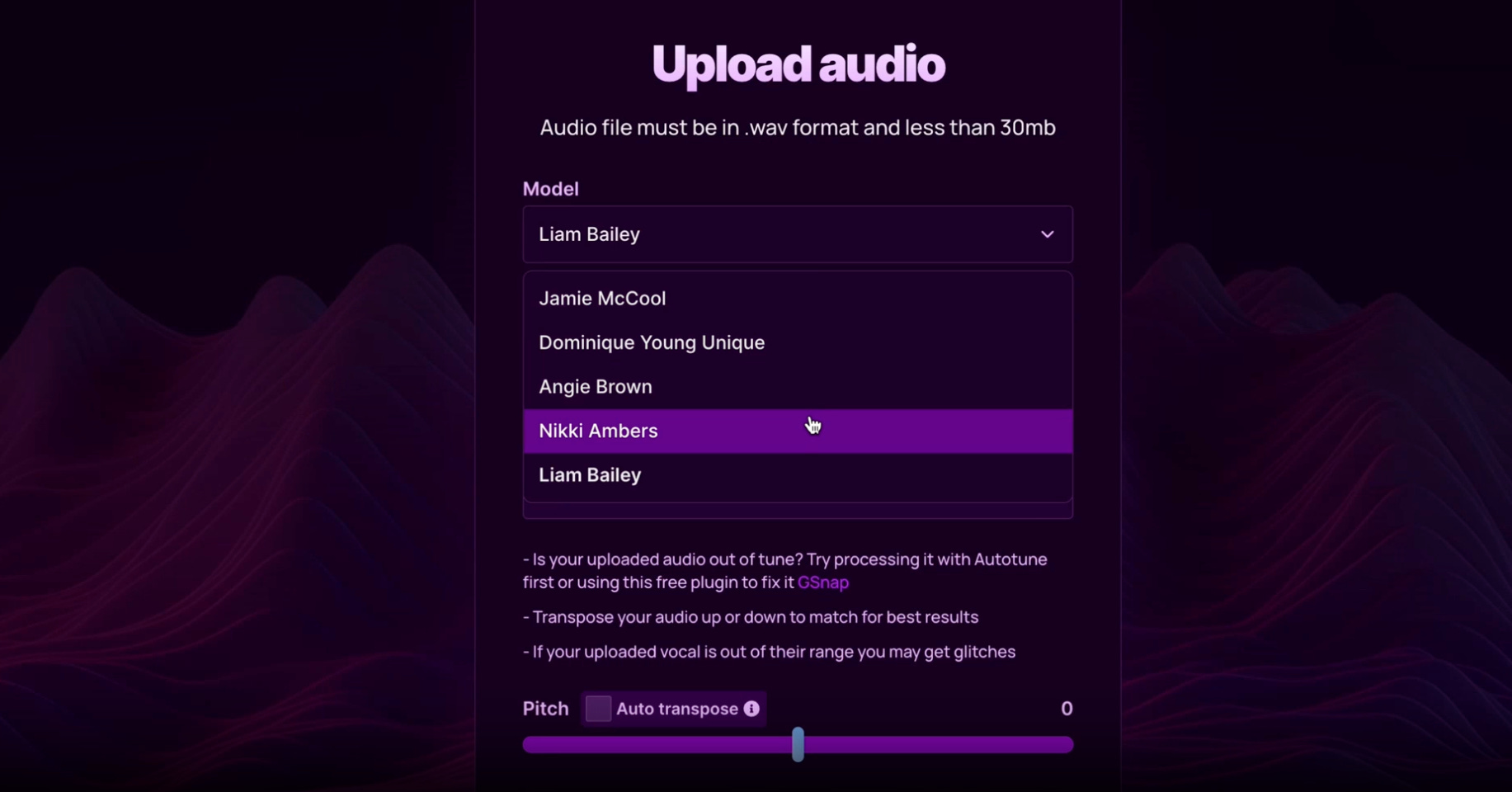
Another chord that struck artists was the ability to capture their voices as they are today.
“We’ve had quite a few people, which I was really surprised to hear, say they like the idea of it because their voice is changing and it doesn’t sound how it did 20 years ago, and this is a tool they can use to immortalise their voice,” explained Stein.
“[Liam Bailey] is writing for Paloma Faith at the moment and he said: ‘Wow if there’s a Paloma Faith model I would be able to write these songs and hear them in her voice and I could send them to her?’ and something switched in his mind and he was amazed.” – DJ Fresh
VOICE STEALING
VoiceSwap Ts&Cs require anyone who uses their models to refrain from posting anything on social media or releasing any music without the artist’s permission. To combat the inevitability of unauthorised use, VoiceSwap has developed a patent-pending watermark technology for their models. “This allows us to track from who’s been using our platform to the person who created the audio. We’re making people sign waivers and creating a very solid legal mechanic to take action against people that do break the law. Ultimately I think if people understand the limitations, most people won’t do that.”
For Stein, the genie is out of the bottle and creating a legal and ethical framework is the way forward, rather than ignoring the technology or abandoning copyright entirely.
“We either find a way to make it work, which will be an iterative process that won’t happen overnight, or we just say ‘None of that matters anymore,’ which is how some [AI] companies feel. They’re saying: ‘The days of copyright and legislation are over you need to accept that AI is here to stay and we need to make it work’, and that’s just not true.”
ARTIST COMPENSATION
Once the legal framework is in place, what kind of compensation can artists expect from VoiceSwap? For Stein, it’s an opportunity to undo some of the wrongs that so often make up legacy deals with major labels.
“As an artist myself, looking at the deals and royalties that exist at the moment, I don’t think it’s fair,” Stein explained. “The artists are being compensated as if they’re the least important part of the equation and I think it should be the other way around. What we’re doing is paying a percentage – a very big one – of our gross income straight to the artists.”
Stein also believes these types of voice model stores could trigger more session work, as producers might use the model to demo their track, but hire the singer to re-record the idea in the studio for the full release. “Angie Brown, for example, can do about 40 different tones with her voice and the AI model takes what you give it – my voice for example, I can only do what I can do. So even though it sounds good and sounds like Angie, it’s never going to be as good as going in the studio with the real singer.”
VoiceSwap is live now – find out more on their FAQ page here.

A NEW LAB
Another AI voice model store that’s popped up recently is Kits.ai, from the team behind the blockchain DAW Arpeggi Labs. Kits.ai offers a series of royalty-free voices, for anyone to use for free for personal use – such as social media content – and with permission for commercial use – like a Spotify release. On top of those royalty-free models, there’s the Artists Voice section, which is behind a paywall of $9.99 per month. Where the royalty-free models are trained on session singers, the Artist Voice section is trained on more established names like Reo Cragun, Edwin Honoret and Sophia Galaté.
Again, artist compensation and protection are key. Pastan says they’re working on two fronts to stop fraud.
“Beyond our in-app personal and commercial approval flow [full details of that license are here], we comprehensively track users who access and use artist models as well as the input and output files and are able to support artists in any case of potential fraud.
Monetisation from Kits.ai comes from the subscription revenue, as Pastan explains:
“For Grimes – there’s lots of branding and marketing upside for her – but the financial success would come from derivative works. We think we can actually pay artists before derivative works even get there. We take subscription revenue and at the end of every month, we look at how often each artist model has been used and then we pay them according to how much revenue comes in.”

Right now, there’s an unlimited amount of downloads per subscription, but Pastan says that might change in the future. Much like Gleeson, he’s wary of creating too rigid a framework when the technology is so new and constantly evolving. “We need to learn about building a tool that makes a lot of sense for artists, and a lot of sense for users and that there’s long-term success and it becomes something viable. So we’ve taken a gentle and artist-forward approach to this – we’re not taking any of the subscription [revenue] as of today, it all goes to artists.”
Despite Kits.ai’s fairly recent launch, the response has been remarkable and points to the potential of these AI voice model stores. “We’ve had over 10,000 users in the past week, with over 100,000 unique audio file conversions. It’s been an amazing and really successful launch and it’s really exciting.”
“We need to learn about building a tool that makes a lot of sense for artists, and a lot of sense for users and that there’s long-term success and it becomes something viable. We’re not taking any of the subscription [revenue] as of today, it all goes to artists.” – James Pastan, Kits.ai
WHAT’S NEXT?
I’ve taken a snapshot of three different use cases for distributing voice models as of early July 2023. The reason I add the date is that things are changing – fast. The upside is that all three are putting artists first. Could Herndon’s Holly+ and Grimes’s Elf Tech end up defining the framework for how artists are compensated for their models, or is it only a matter of time before more VCs roll in and artist consent is thrown out the window? (Life hack: Google ‘OpenAI sued’ for the latest on how that’s going).
Maybe I’m an optimist but I’m hopeful that models like these can give artists back autonomy over their talent. With so many legacy deals gone sour, this could be a chance to right the wrongs of the past and create a genuine new revenue stream for artists and musicians who have struggled in the age of streaming. Yes, things like sample packs have always been an option for producers, but their market was limited to their peers. This technology in its essence is truly accessible, and has the potential for incredible scale, with meaningful and dignified income for those behind the models.
There are, of course, significant downsides – a nightmare-fuelled content farm of deep fake singers will likely emerge, as well as a wild west period of fraudulent models and unauthorised uploads. There are also the existing quality issues, where artefacts leak in and affect the sound of the output – though I do think this will become a sought-after aesthetic, as autotune did. Appropriation is also a concern, as Black vocalists, especially females, were so often exploited in the early days of house music. And yes, we will for sure see dystopian models of deceased artists created by their estates looking to cash in.
But I’m not sure that should prevent us from looking for solutions and a positive path forward. The creative and practical potential for producers and artists, as well as the novelty appeal to the mass market, means that this isn’t going to go away. If IP, copyright and ethical concerns are addressed, there’s no reason this can’t be a thriving new ecosystem that could redefine music creation entirely.
Recommended Reading
AI Futures: How Artificial Intelligence Will Change Music (DJ Mag, 2021)
Paradigm Shift: How AI Will Transform Music Creation in the Next 10 Years (Water & Music, 2022)
Interview: Mat Dryhurst & Holly Herndon (FACT, 2023)
You Are Grimes Now: Inside Music’s Weird AI Future (Rolling Stone, 2023)
Other recommended stuff from the internet
Paul Graham wrote this very long and very thought-provoking essay on How to Do Great Work. If you’ve ever tried to do something creative or entrepreneurial, I highly recommend you read it.
I’m almost finished the excellent book ‘God, Human, Animal, Machine’ by Meghan O'Gieblyn. You might have heard her interviewed on Sean Illing’s The Grey Area, and mentioned on Ezra Klein’s podcast – two huge endorsements as far as I’m concerned. It dissects how AI and spiritualism overlap and the power of anthropomorphism, for good and bad. Highly recommended.
Not a brand new piece but worth reading for context around existing AI hype – The Verge’s Inside the AI Factory.
Water & Music founder and general music tech icon Cherie Hu was the guest on RA’s Exchange podcast this week.